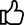The main concern that any web retailer ever faces is the fear of Duplicate Content. For raising organic traffic to any website, Duplicate content is one of the biggest enemies since Google rankings are based purely on Original Content created. Many sites copy content from other sites that is no good for their online business growth as they can penalized and also taken off the rankings for indefinite period. If you are looking forward to remove duplicate content from your website than you should do quickly since it requires few technical changes. In a matter of few weeks, you can see your website is fairing better and has got improved rankings. Removing duplicate content is not just about removing penalties but helps for building the links. Links are a valuable resource for better SEO performance.
The given below is an example of Diluted Links because of Duplicate Content. The same content when searched by several URLs dilutes the online reputation. The image shows three different pages of the same product. When searched by users, search engines scans through each page checking the popularity of the pages and how often the users have visited it. They consider overall quality and quantity from third party sites as the kind of endorsements. Search engines use the links to prioritize how far they search, what is the ranking, what is indexation, how much they rank and how higher they rank.

Source: Google
The main page reputation is hampered because the other pages receive some reputation online because they are having the same content. They may even have same set of keywords that are searched. By consolidation of the duplicates, we increase links to main page and hence boost the reputation.
Now, the main question is HOW does one Detect Duplicate Content. This is a very simple step by which you will know whether your site reputation is hampered or not. To determine, type in Google – yoursitename.com and you will see the list of sites listed having duplicate content.
To determine if your site has duplicate content, type in Google site:yoursitename.com, and check how many pages are listed. Usually the products on your site make up the pages that are listed on search engines and if it shows bulk pages with given keywords it shows that it has duplicate content. XML sitemaps are comprehensive hence Google search console could be used to compare number of pages indexed in XML sitemaps as opposed to the number of total indexed pages in your Index status.

Blocking duplicate pages by making use of robots.txt, the duplicate pages are still able to accumulate links and it doesn’t hamper their page reputation. It’s basically an outdated technique that does not consolidate reputation of duplicate links in canonical pages.
RewriteEngine On – it will help enable Rewrite capacities
RewriteCond %{HTTPS} !=on – the command helps to make sure the connection is not already HTTPS
RewriteRule ^/?(.*) https://www.webstore.com/$1 [R=301,L]

This is done to check the connection whether it is already HTTPS or not.

The rule is applied to address rare IP duplication where site is available through the IP address.
RewriteEngine On – helps to rewrite the capabilities
%{REQUEST_FILENAME} !-f – This command makes sure that slashes are not added to the files. i.e., /index.html/ would be incorrect.

This rules helps to add missing trail slashes. The given below helps to remove them:

This is perhaps one of the most common duplicate file cases, it is the director index file. We have to remove the directories index.php and .NET systems to avoid the duplication.

In the above example, one can note that the product IDs are same for both the URLs. The canonical version and the other one is the duplicate. Because of this, one can use single rule to map all product pages. The product IDs are not same and new URLs don’t use same IDs, you will require one-to-one mappings. The available tools online helps to map and rewrite the products.